
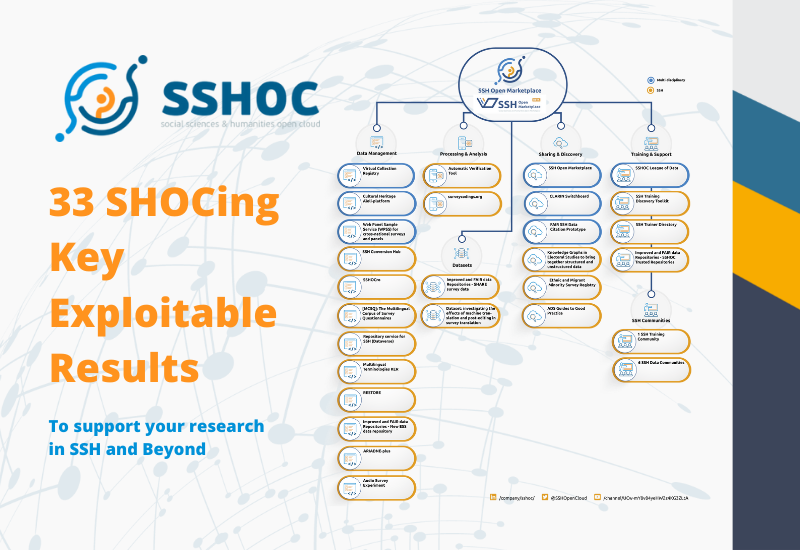
Between January 2019 and April 2022 SSHOC will deliver a series of services and tools for daily use by SSH researchers.
These tools and services are defined as “Key Exploitable Results”, as they will be available for further research activities after the end of the SSHOC project.
The following table identifies all SSHOC Key Exploitable Results and maps them according to their category.
|
Data Management |
|
|
The Virtual Collection Registry (VCR) enables researchers to create, register and manage virtual collections that are integrated, coherent sets of links to distributed resources of interest for the virtual collection creator and user. Each virtual collection comes with a persistent identifier and FAIR metadata. |
|
|
An innovative web service for the reality-based 3D annotation and large-scale collaborative documentation of heritage artefacts. The existing Aïoli platform has been significantly upgraded in terms of technical robustness, the collaboration framework was provided, the management of controlled vocabularies, and compatibility with CIDOC-CRM was established. |
|
|
Web Panel Sample Service (WPSS) for cross-national surveys and panels |
This is a secure sample management web application coupled with a survey platform (a Qualtrics dedicated license) to meet the needs of high-quality cross-national probability-based online panels. The service has been named WPSS (Web Panel Sample Service). |
|
A registry of (meta)data conversion services and solutions featuring the most relevant SSH (meta)data formats as recommended by SSHOC and encompassing links to services. |
|
|
SSHOCro is a workflow model which aims to describe the entire data life cycle in social sciences and humanities research including both the generation and the processing of the data. |
|
|
Archaeological data management best practice guidance developed within E-RIHS and SSHOC will be implemented within the ARIADNEplus infrastructure and workflow, which may then be made available as a service within SSHOC. |
|
|
MCSQ is a multilingual corpus compiled from questionnaires from the ESS, the EVS, SHARE and WIZ in (British) English source language and their translations into Catalan, Czech, French, German, Norwegian, Portuguese, Spanish, Russian, as well as 29 language varieties (e.g., Swiss-French, Austrian-German). It is freely accessible through an interface. Datasets can be customized and downloaded. The corpus is sentence aligned with respect to the source and allows for the possibility of creating translation memories. The MCSQ functions both as a repository of previous rounds of survey texts and a tool for systematic analysis of previous translation decisions. Before the compilation of the MCSQ, no method for tracing translation decisions systematically in multilingual surveys has been in place. |
|
|
The repository service for SSH is built upon the community-driven open source Dataverse software. Its modular design facilitates integration with other data services such as DataCite or ROpenSci, CLARIN’s Language Resource Switchboard, and supports the development of additional functionality and services. Two types of services are being developed: 1) a central (ERIC-level) service in the cloud, adapted to the needs of the relevant European SSH community, for small institutes to have a research data repository for their designated community. |
|
|
|
A set of multilingual metadata is provided by using Machine Translation services with human validation, with particular attention on highly specialized sectors. Multilingual terminologies are created collecting standards and other technical documents on Data Stewardship and extracting terms with NLP techniques. For each term a definition is also collected. The collected terms are used to enrich other existing terminologies, and in particular to Loterre Open Science Thesaurus. Validated terms, their definitions are translated using MT translation services and their translations will be made available as SKOS resources. |
|
RESTORE releases a digital platform for mapping, integration and reuse of heterogeneous datasets, focusing on the recovery, integration, accessibility and reuse of digital resources, provided by GLAM (Galleries, Libraries, Archives, Museums) institutions, research centres and conservation laboratories. Materials are collected, mapped, transformed and stored for access and reuse, according to the CIDOC-CRM ontology. |
|
|
Improved and FAIR data Repositories - New ESS data repository |
ESS data and documentation available to users from the new repository accompanied by interoperable services. ESS data can be combined with other types of data from various domains by aggregation to the same regional levels. Data are relevant for various types of users including for policy makers. |
| The Audio Survey Experiment provides guidelines describing how to integrate the collection of digital language data into the traditional social sciences data collection process and provides audio transcript data which can be analysed with the help of natural language processing tools. | |
|
Datasets |
|
|
Dataset: investigating the effects of machine translation and post-editing in survey translation |
Dataset of two experiments in the language pairs English-Russian, English-German. The dataset contains linguistic data (Segments translated in different methods) and human data (participants filled in questionnaires). The dataset contains translation versions across different steps of a team translation approach. |
|
Technological development continues to offer ways of health data collection that go beyond asking survey questions. Such new types of data were collected in the SHARE survey by means of Dried Blood Spot Samples (DBSS) and accelerometer data. These data demand new data protection rules and must often be extensively processed, validated and calibrated before they can be made accessible. SHARE and CentERdata develop a strategy to provide access to such data according to FAIR principles. |
|
|
The Audio Survey Experiment provides guidelines describing how to integrate the collection of digital language data into the traditional social sciences data collection process and provides audio transcript data which can be analysed with the help of natural language processing tools. |
|
|
Processing & Analysis |
|
|
The Automatic Verification Tool (AVT) enables the user to verify translations using Bilingual Word Embeddings and to report to the translators a set of translated questions to be re-checked. The AVT imports the questions and makes use of a trained Bilingual Word Embeddings model. It generates the 10 best foreign language translations of each English word. If one of the best translations is in the human foreign language translation it marks the word pair as matched. By measuring the number of matched word pairs it estimates the translation quality. It stores the translation quality scores and reports them to the user. |
|
|
Surveycodings offers a host of social science codings measuring individual and socio-economic variables. The developed tools consist of a multilingual repository containing questionnaires, data collection tools, and coding frames based on standard statistical classifications covering a large number of countries. The variables included within the project are the following: occupation, industry, levels and fields of education, region, food groups, religions, cost of living, and marital status, all coded according to ruling standards. The benefits of such a tool are 1) reduced manual post-coding, 2) less harmonization logistics, and 3) decreased costs by linking survey questionnaires to databases to allow the coding of survey variables during the interview. |
|
|
Sharing & Discovery |
|
|
CLARIN's original Language Resource Switchboard matches language resources with suitable processing tools, automatically guiding researchers to the appropriate language analysis application. SSHOC has extended the Switchboard to provide support for broader data types used in Humanities and Social Sciences research, e.g. tabular data with geographic coordinates. Additional information directed at a broader SSH audience was created and a workshop directed at SSH researchers is organised to test and obtain further feedback about the Switchboard use in researcher workflows. |
|
|
The FAIR SSH Data Citation prototype is a software tool designed and developed in the SSHOC project to support the process of creating FAIR SSH citations. As described in SSHOC Deliverable 3.5, main steps to build a FAIR SSH citation are:
The prototype provides functionalities to retrieve and collect metadata related to the cited Digital Object and enables (i) users to visualize the metadata using a web based GUI and (ii) software agents to download the metadata as a JSON object. The retrieved metadata, then, could be used to annotate the original citation. |
|
|
Knowledge Graphs in Electoral Studies to bring together structured and unstructured data |
The Electoral Studies Knowledge Graph Pilot provides a web-based knowledge and information discovery application for professionals and scientists in the field of electoral studies. Based on a comprehensive Knowledge Graph on Electoral Studies (a Knowledge Graph is a knowledge base that is enriched with data and documents that are interlinked with each other based on the underlying knowledge model) the user can search and explore for relevant information - in the pilot system: research methods, research concepts, and publications - in one single point of access instead of time consuming searching and browsing inside of several information and data repositories. |
|
The Ethnic and Migrant Minorities (EMM) Survey Registry is a free online discovery tool and database that displays detailed information (i.e. metadata) about existing quantitative sample-based surveys conducted with EMM populations in Europe. Jointly developed by SSHOC, the COST Action 16111 – ETHMIGSURVEYDATA (a network of 200+ EMM researchers across Europe), and a French Agence Nationale de la Recherche (ANR)-funded project, FAIRETHMIGQUANT, the EMM Survey Registry promotes the FAIR principles and provides a concrete example of how an interdisciplinary data community can drive the creation of a FAIR-friendly tool for the social sciences using a bottom up, collaborative approach for the benefit of a wide range of stakeholders. The EMM Survey Registry is intended for use by researchers, policymakers, and other practitioners in their own research and/or policy-related activities. As a model of co-creation it will be of interest to data communities committed to making their data FAIR, to data curation actors looking to partner or connect with data producers or users for whom they can tailor their current data curation services, and to policy-makers working on open research and open data initiatives. |
|
|
The ADS Guides to Good Practice represent the international standard for archaeological data management best practice. The Guides incorporate the understanding developed around archaeological data from the wide range of EC research projects, and can be a resource within EOSC for SSH data management. |
|
|
Training & Support |
|
|
The SSHOC League of Data will engage researchers in a game to learn how to manage their research data, from the first plan to the making their data widely available for discovery. |
|
|
The SSH Training Discovery Toolkit (“Toolkit” in short) is an inventory of various learning and training materials that trainers of different disciplines in the SSH can use to find materials for re-use in their own training. The Toolkit links to a variety of materials available through various sources on topics including Open Science, Research Data Management, and didactics, but also specific topics that are relevant to multiple disciplines, like text encoding and spatial data. While the Toolkit does not store the resources themselves, it contains access links that redirect the user to the resource in question. The Toolkit is a work in progress and currently contains more than 180 items from 78 different sources on the above-mentioned topics for better development and implementation of training activities. |
|
|
The Trainer Directory is an inventory of trainers in the field of SSH that provides an overview of their expertise and training they provide. The directory can be used by people looking for a trainer to find one that may suit their needs. It can also be valuable for trainers to increase their visibility and promote their services. |
|
|
Improved and FAIR data Repositories - SSHOC Trusted Repositories |
SSHOC promotes trust and quality assurance by supporting data repositories in their journey to CoreTrustSeal certification. Fourteen data repositories were selected for certification support through an open call between June and August 2020. These repositories are in varying stages of preparation with some closer to being ready to apply for certification and others more focused on taking note of issues and establishing best practices. The work of the SSHOC certification task team is to meet repositories at their point of readiness and provide assistance and guidance related to the certification process along with feedback on the repositories’ self-assessments before they submit their applications to CoreTrustSeal. SSHOC works in cooperation with FAIRsFAIR and with other EOSC projects which also have activities to support the certification of data repositories. FAIRsFAIR, for instance, aims to align the FAIR Principles with the CoreTrustSeal requirements. The EOSC Executive Board FAIR Working Group has published Recommendations on certifying services required to enable FAIR within EOSC. Supported repositories
|